# Configure Ellucian Banner as your data pipeline source
Set up Ellucian Banner as a data pipeline source to extract and sync records into your destination. This guide includes connection setup, pipeline configuration, and key behavior for working with your Banner environment.
# Features supported
The following features are supported when using Ellucian Banner as a data pipeline source:
- Extract and sync data using the Ellucian Ethos Integration APIs
- Support for full and incremental sync
- Field-level selection for data extraction
- Schema drift detection and handling
- Field-level data masking
# Prerequisites
You must have the following configuration and access:
- Access to your Ellucian Banner Cloud environment
- An Ethos Integration API key
- Region and domain details for your Ellucian Cloud
# Connect to Ellucian Banner
Complete the following steps to connect to Ellucian Banner as a data pipeline source. This connection enables the pipeline to extract and sync records from your Ellucian environment.
Connect to Ellucian Banner
Select Create > Connection.
Search for and select Ellucian Banner on the New connection page.
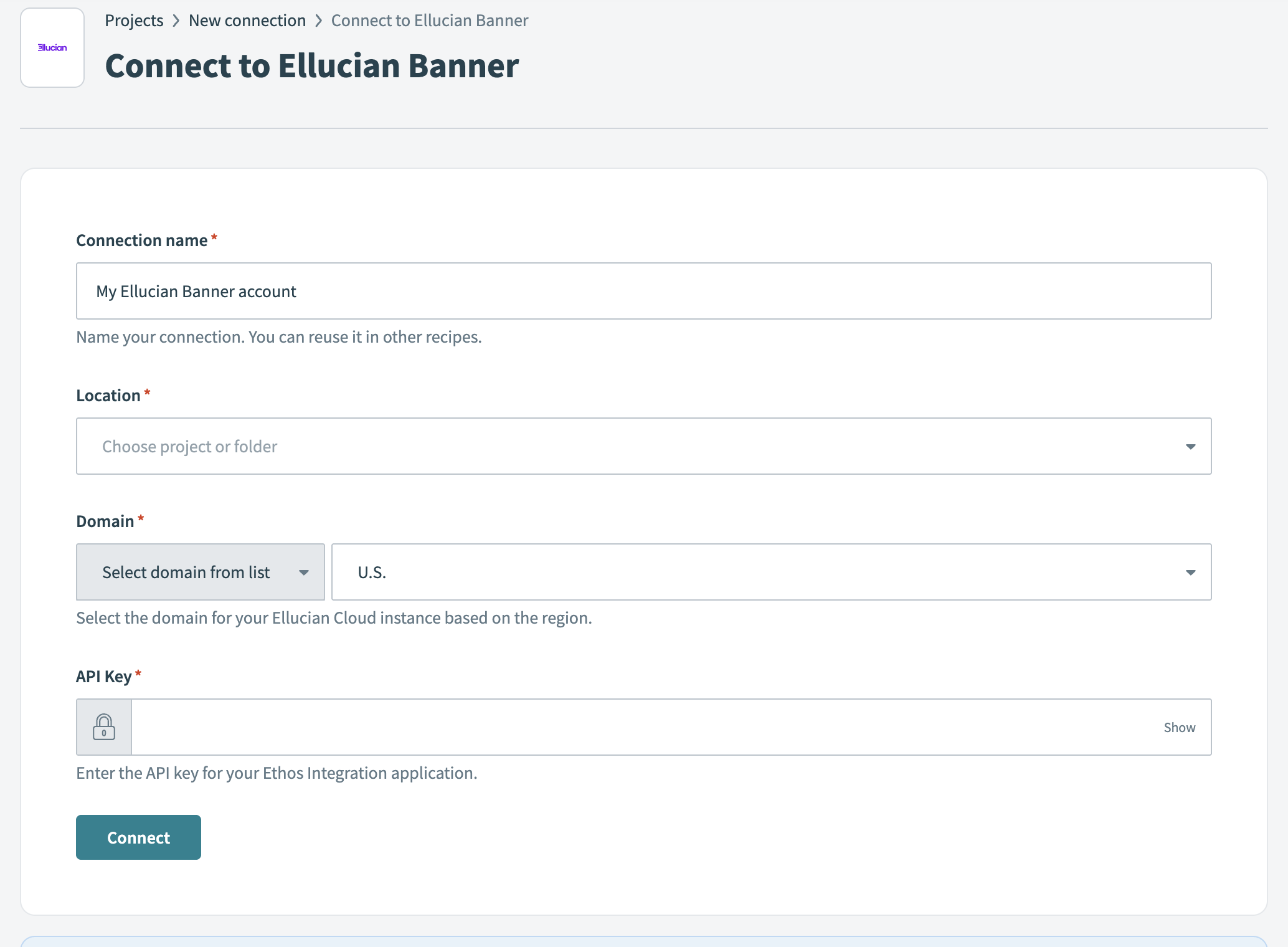
Enter a name in the Connection name field.
 Ellucian Banner connection setup
Ellucian Banner connection setup
Use the Location drop-down to select the project where you plan to store the connection.
Select Cloud in the Connection type field, unless you need to connect through an on-prem group.
Select your region from the Domain drop-down. Choose the domain based on the location of your Ellucian Cloud instance (for example, U.S., Canada, or Europe).
Enter your API key. This is the API key for your Ethos Integration application in Ellucian.
Select Connect to verify and store the connection.
# Configure the pipeline
Complete the following steps to configure Ellucian Banner as your data pipeline source.
Select Create > Data pipeline.
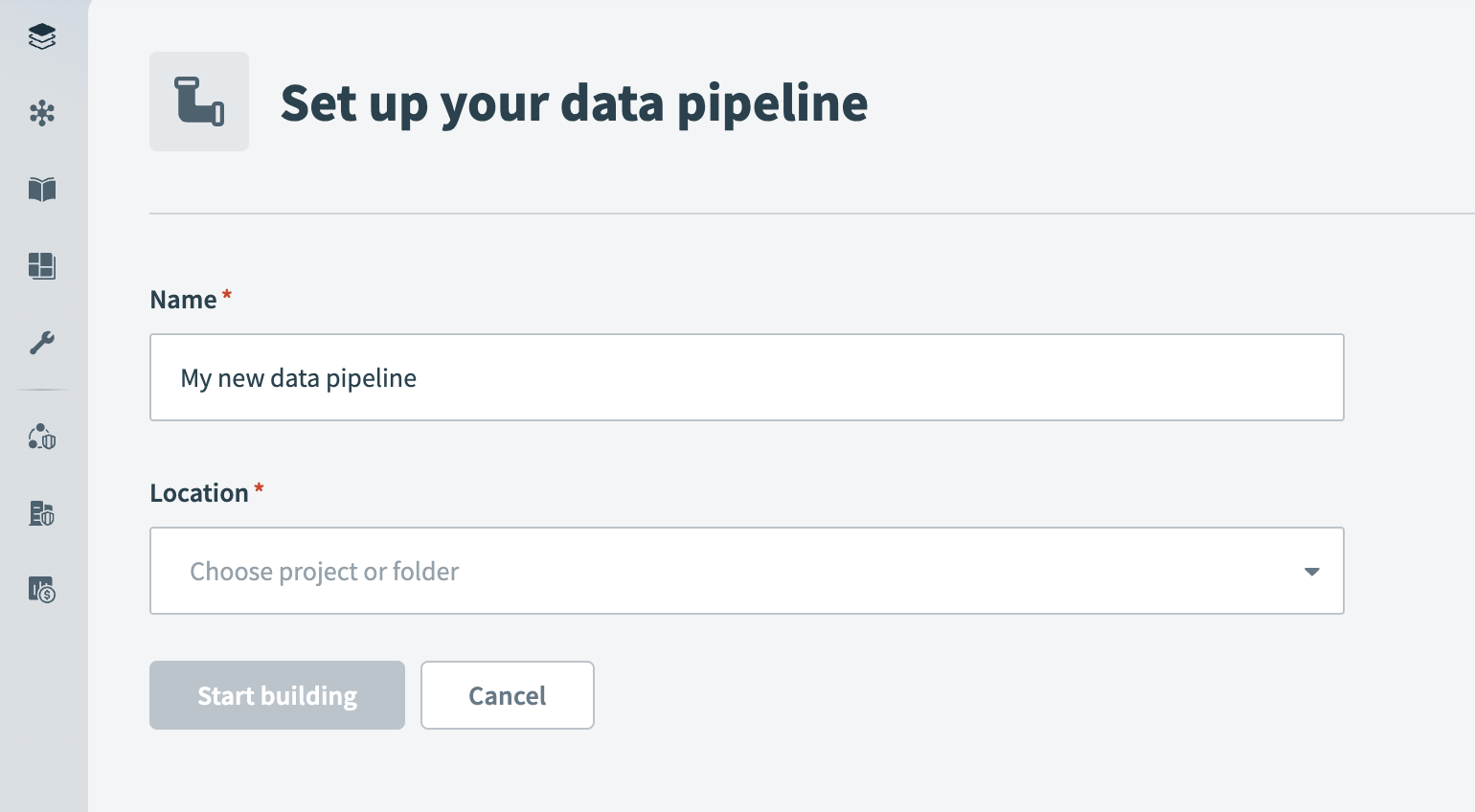
Provide a Name for the data pipeline.
 Data pipeline setup
Data pipeline setup
Use the Location drop-down menu to select the project where you plan to store the data pipeline.
Select Start building.
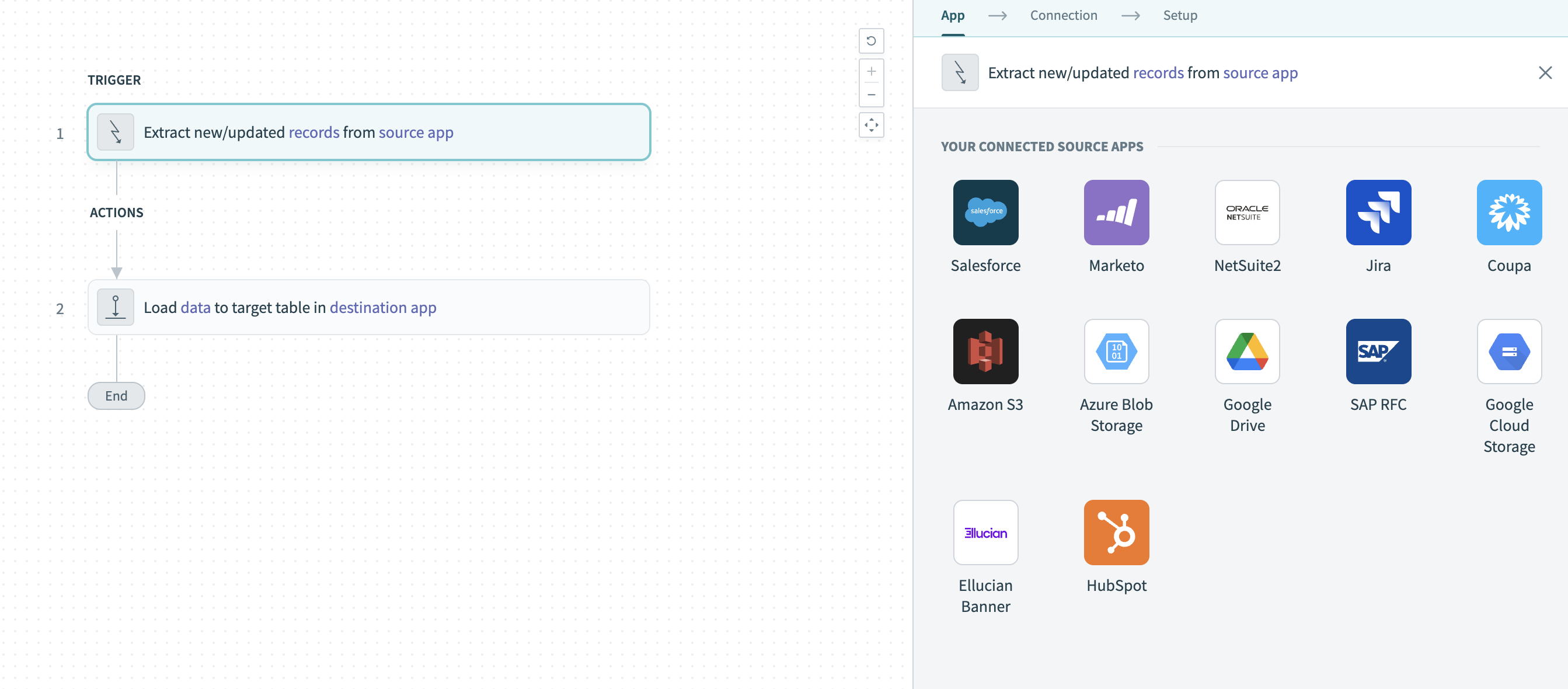
Click the Extract new/updated records from source app trigger.
 Configure the Extract new/updated records from source app trigger
Configure the Extract new/updated records from source app trigger
Select Ellucian Banner from Your Connected Source Apps.
Choose the Ellucian Banner connection for this pipeline. To create a new connection, select + New connection.
Click Add object to open the object wizard.
Search or browse the list of available Ellucian Banner objects. Select the objects you plan to sync and click Add.
Review and customize the schema for each selected object. When you select an object, the pipeline automatically fetches its schema to ensure the destination matches the source.
Expand any object to view its fields. Keep all fields selected to extract all available data, or deselect specific fields to exclude them from data extraction and schema replication.
Optional. Configure field-level data protection. After you expand an object, choose how to handle each field:
- Replicate as is (default): Data values at the source are replicated identically to the destination.
- Hash: Hash sensitive data values in the column before syncing to your destination.
Click Add object again to add more objects using the same flow. You can repeat this step to include multiple Ellucian Banner objects in your pipeline.
Choose how to handle schema changes:
- Auto-sync new fields to detect and apply schema changes automatically
- Block new fields to manage schema changes manually
Refer to the Schema drift section for more information.
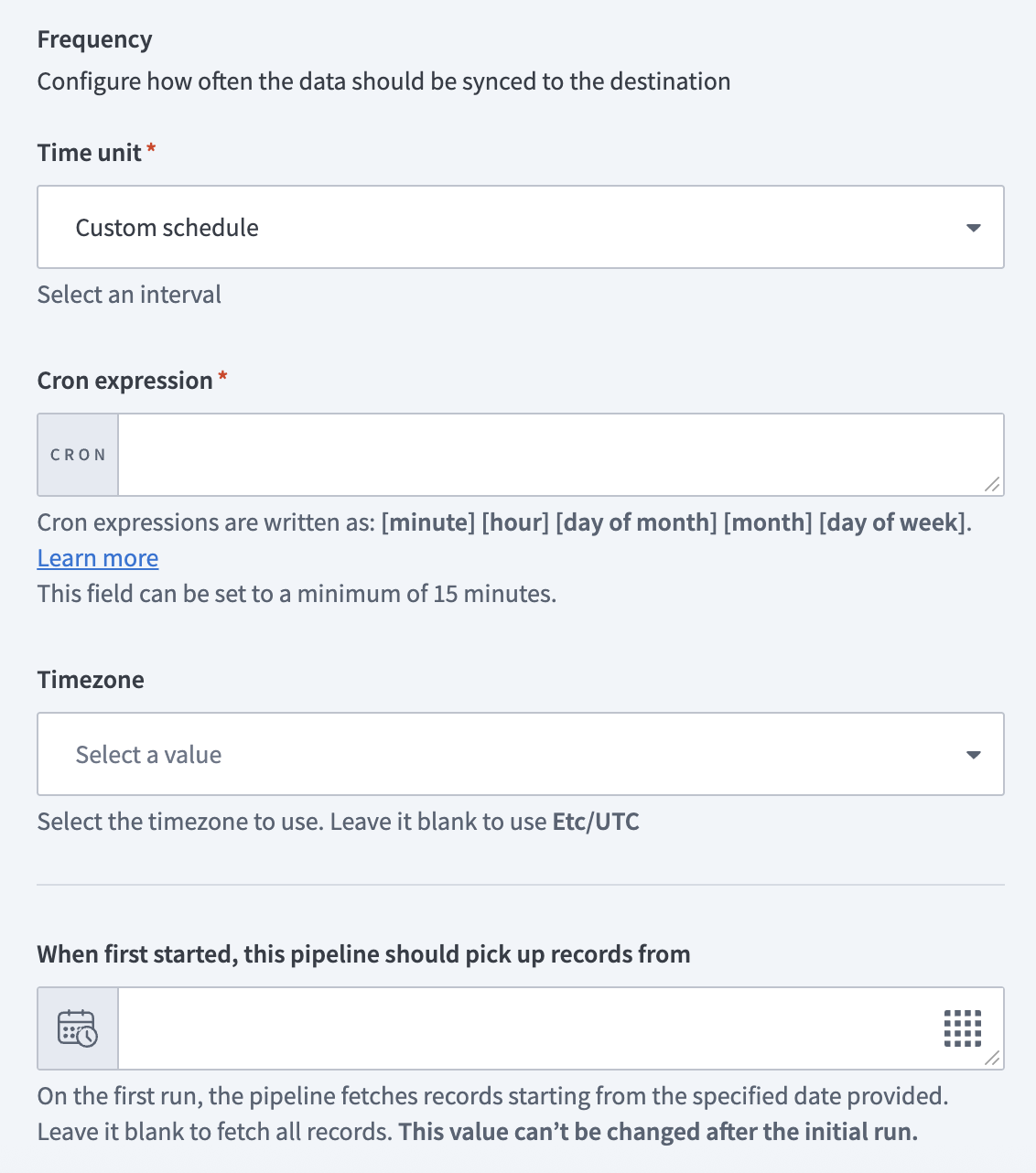
Configure how often the pipeline syncs data from the source to the destination in the Frequency field. Choose either a standard time-based schedule or define a custom cron expression.
 Configure sync frequency
Configure sync frequency# Object schema behavior
The Ellucian Banner connector extracts records from objects exposed through the Ethos Integration API. These objects define the schema used by the pipeline.
Workato infers schema and data types from the selected reference object at the time of configuration. The structure of each object must remain consistent to ensure accurate schema mapping and reliable data replication.
Last updated: 2/6/2026, 5:48:07 PM