BigQuery - BigQuery へのデータの挿入
Workato には、BigQuery にデータを送信するための4つの異なる方法があります。
単一行の挿入
このアクションは、ストリーミングを介して BigQuery 内のテーブルに単一の行を挿入します。1日にストリーミングできる行数に制限はありません。複数行がストリーミングされると、このデータをコピーやエクスポート操作で使用できるまでに最大90分かかることがあります。サンプルレシピ
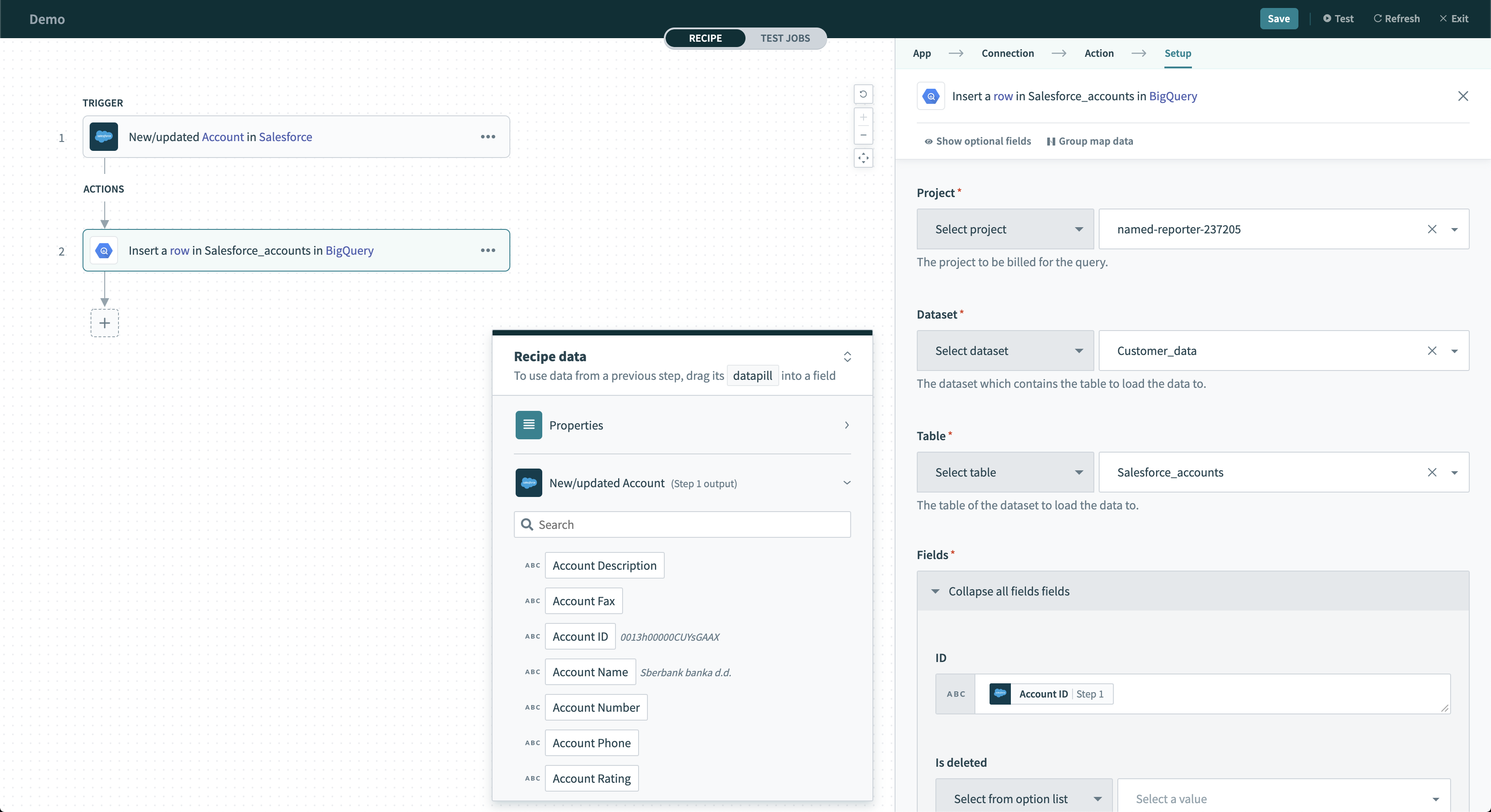 Insert row アクション
Insert row アクション
入力項目
| 項目 | 説明 |
|---|---|
| Project | クエリーの課金対象となる、コネクションで利用可能なプロジェクトです。 |
| Dataset | アクションまたはトリガーが使用可能なテーブルをプルする元となるデータセットです。 |
| Table | データセット内のテーブルです。 |
| Ignore schema mismatch | [No] に設定すると、ストリーミングされる値が予期されるデータ型と一致しない場合にエラーがスローされます。これらの行を無視するには、[Yes] に設定します。 |
| Fields | 選択したテーブルの列です。 |
| Insert ID | ストリーミング時に行の重複を削除するために使用されます。ID が同じ行は BigQuery で再度ストリーミングされることはありません。 |
出力項目
| 項目 | 説明 |
|---|---|
| Errors | この行のストリーミング中に発生したすべてのエラーが含まれます。この項目を使用して、行の挿入でエラーが発生したかどうかを確認し、必要に応じて再度ストリーミングすることができます。 |
バッチ行の挿入
このアクションは、ストリーミングを介して BigQuery 内のテーブルにバッチ行を挿入します。1日にストリーミングできる行数に制限はありません。複数行がストリーミングされると、このデータをコピーやエクスポート操作で使用できるまでに最大90分かかることがあります。サンプルレシピ
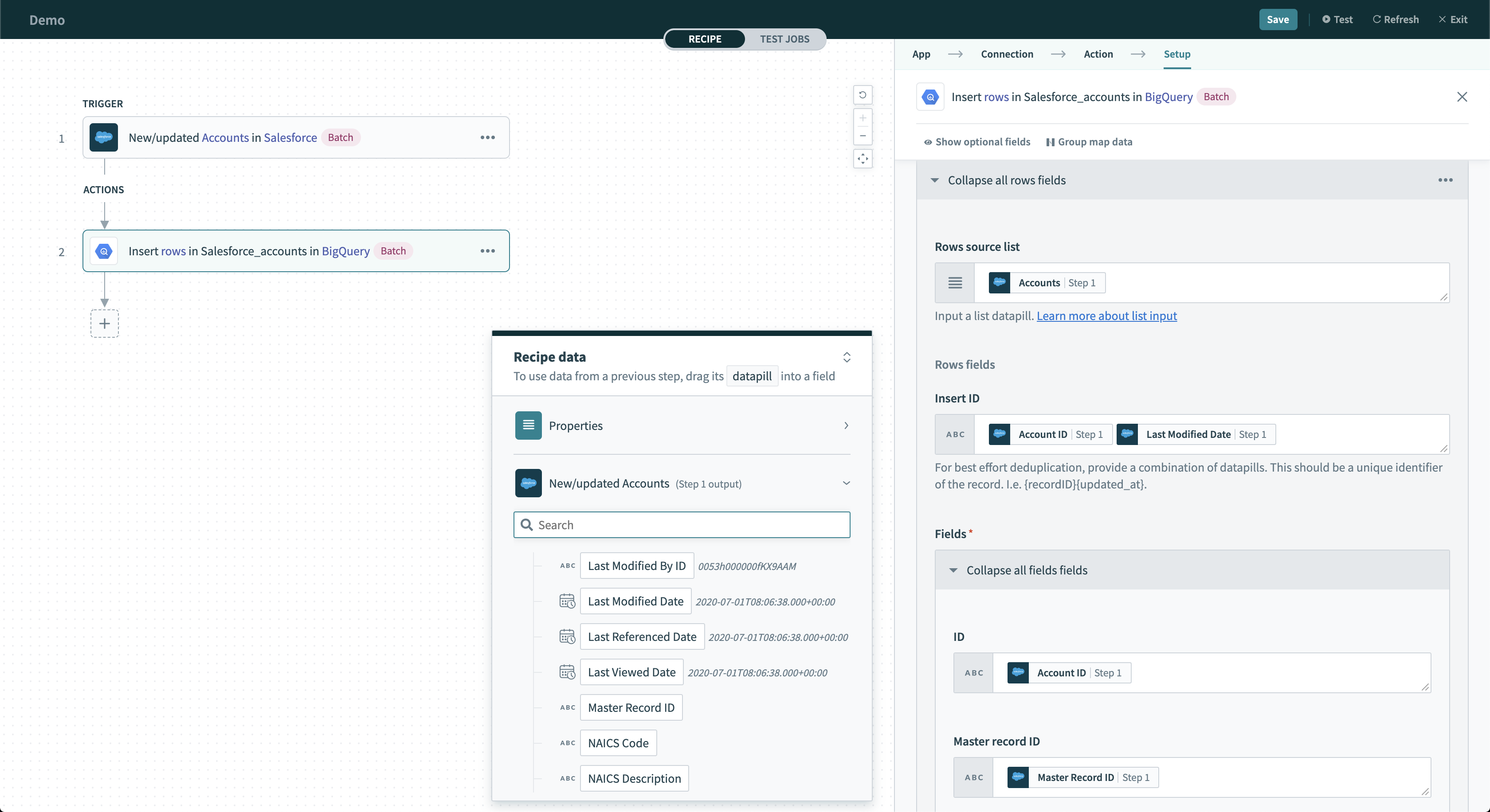 Insert rows アクション
Insert rows アクション
入力項目
| 項目 | 説明 |
|---|---|
| Project | クエリーの課金対象となる、コネクションで利用可能なプロジェクトです。 |
| Dataset | アクションまたはトリガーが使用可能なテーブルをプルする元となるデータセットです。 |
| Table | データセット内のテーブルです。 |
| Ignore schema mismatch | [No] に設定すると、ストリーミングされる値が予期されるデータ型と一致しない場合にエラーがスローされます。これらの行を無視するには、[Yes] に設定します。 |
| Fields | 選択したテーブルの列です。 |
| Insert ID | ストリーミング時に行の重複を削除するために使用されます。ID が同じ行は BigQuery で再度ストリーミングされることはありません。 |
出力項目
| 項目 | 説明 |
|---|---|
| Insert Errors | 各行のストリーミング中に発生したすべてのエラーが含まれます。この項目を使用して、行の挿入でエラーが発生したかどうかを確認し、必要に応じて再度ストリーミングすることができます。 |
| Failed rows | 失敗した各行についてのデータが含まれます。この項目を使用して、行のストリーミングを再試行できます。 |
ファイルまたは Google Cloud Storage からのデータの読み込み
ファイルデータを読み込むことで、何百万もの行を BigQuery テーブルに効率的に挿入できます。大規模なフラットファイルを使用している場合、この自動化戦略によって、テーブルに挿入できる行数や行の挿入にかかる時間の点でパフォーマンスが大幅に向上します。
BigQuery コネクターには、 BigQuery にファイルデータを読み込む方法が2つあります。1つはレシピの前のステップでダウンロードしたファイルから読み込む方法、もう1つは Google Cloud Storage の既存のファイルから読み込む方法です。Workato では、まずファイルを Google Cloud Storage にアップロードして、そこから Google BigQuery に読み込むことをお勧めします。
この強力なアクションでは、大量の行を移動させるだけでなく、読み込む CSV または JSON ファイルの列数の変化を検出して、それを受け入れるよう BigQuery 内のテーブルのスキーマを拡張させることができます。
注 BigQuery では読み込む CSV および JSON ファイルのスキーマを検出できるため、テーブルスキーマを指定する必要はありません。 検出されない場合、テーブルスキーマを手動で定義する必要があります。読み込み先のテーブルと異なる列がファイルに含まれる場合は、Alter table columns when required? を使用して、BigQuery でテーブルの列を拡張することができます。
入力項目
| 項目 | 説明 |
|---|---|
| Project | クエリーの課金対象となる、コネクションで利用可能なプロジェクトです。 |
| Dataset | アクションまたはトリガーが使用可能なテーブルをプルする元となるデータセットです。 |
| Table | データセット内のテーブルです。新しいテーブルを作成する場合は、[Enter table ID] に切り替えて目的のテーブル名を入力します。 |
| Source URI ([Load data from Google Cloud Storage into BigQuery] アクションのみ) | Google Cloud Storage 内のファイルのソース URI です。ファイルのソース URI の形式は gs://[BUCKET_NAME]/[FILE_NAME] のようになります。バケット名の後にワイルドカード (*) を使用できます (例 : gs://my_sample_bucket/bulk_load_*.csv)。 |
| File contents ([Load data into BigQuery] アクションのみ) | ストリーミングするファイルのファイルコンテンツです。このファイルには、CSV、Datastore バックアップ、改行区切りの JSON、AVRO、PARQUET、ORC の形式を使用できます。 |
| File size ([Load data into BigQuery] アクションのみ) | 読み込むファイルの正確なファイルサイズです。BigQuery にデータをストリーミングするために必要になります。 |
| Schema | ファイルのスキーマです。[Autodetect] が [No] に設定されている場合にのみ必要になります。 |
| Autodetect | CSV ファイルと JSON ファイルにのみ適用されます。BigQuery はファイルのイントロスペクションを行い、ファイルのスキーマを自動的に検出します。 |
| Alter table columns when required? | 読み込むファイルが読み込み先のテーブル内の列と一致しない場合に、BigQuery でテーブルのスキーマを更新できるようにします。 |
| Create disposition | BigQuery に、必要に応じてテーブルを作成するか、エラーをスローするように指示します。 |
| Write disposition | BigQuery に、書き込みを行う前にテーブルを削除するか、テーブルの末尾にデータを付加するか、テーブルが既に存在する場合にエラーをスローするかを指示します。 |
| Chunk size | BigQuery に送信される各パケット内のチャンクのサイズです。ほとんどの場合、設定する必要はありません。 |
出力項目
| 項目 | 説明 |
|---|---|
| ID | 作成された読み込みジョブの ID です。 |
| Kind | 作成された BigQuery ジョブの種類です。 |
| Self link | BigQuery コンソール内の読み込みジョブへのリンクです。 |
| Job reference | 作成されたジョブについてのデータが含まれます。 |
| State | ジョブが完了したかどうかを示します。常に [Done] である必要があります。 |
| Statistics | 作成された読み込みジョブに関連付けられた統計です。 |
| Status | 読み込みジョブで発生したエラーについての情報が含まれます。 |
| User email | ジョブを作成したユーザーのメールアドレスです。この Workato コネクションに対して認証されたユーザーのメールアドレスになります。 |
Last updated: